Huffman code use case.
Huffman code is a special type of optimal prefix code that is widely used for lossless data compression in information theory and computer science. An algorithm was elaborated by MIT student David A. Huffman. The implementation idea is to set variable-length codes to input characters, lengths of the assigned codes are based on the frequencies of corresponding input characters. In the end the most frequent character obtains the smallest code and the least frequent character receives the largest code.

Python Knowledge Base: Make coding great again.
- Updated:
2026-07-17 by Andrey BRATUS, Senior Data Analyst.
Huffman Coding Python code:
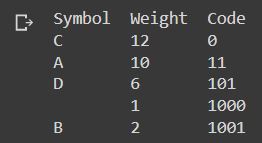
Huffman Coding output:
As in other entropy encoding methods, more common symbols are generally represented using fewer bits than less common symbols. In practice Huffman Coding is generally useful to compress the data in which there are frequently occurring characters. A great use case of Huffman coding is conventional data compression formats like ZIP.
from heapq import heappush, heappop, heapify
from collections import defaultdict
import collections
txt = "BCAADDDCCACACAC BCAADDDCCACACAC"
symb2freq = collections.Counter(txt) #counts letter frequency and puts in dictionary
def encode(symb2freq):
heap = [[freq, [symbol, ""]] for symbol, freq in symb2freq.items()] #converts dictionary to a list in order to sort out alphabets in terms of frequencies
heapify(heap) #Sorting out the list so that 1st element is always the smallest
while len(heap) > 1:#while there is more than 1 element in the list
left = heappop(heap) #Takes the lowest frequency from the list
# print("lo=", left)
right = heappop(heap) #Takes the lowest frequency from the list
for x in left[1:]:
x[1] = '0' + x[1]
for x in right[1:]:
x[1] = '1' + x[1]
add_freq= [left[0] + right[0]] + left[1:] + right[1:] #adds the frequencies and inserts frequency, symbol and alphabet (0 or 1) into one list
heappush(heap, add_freq )#inserts add_freq into heap
return sorted(heappop(heap)[1:], key=lambda p: (len(p[-1]), p))
huff = encode(symb2freq)
print ("Symbol\tWeight\tCode")
for p in huff:
print ("%s\t%s\t%s" % (p[0], symb2freq[p[0]], p[1]))